Test results may help make a diagnosis in symptomatic patients (diagnostic testing) or identify occult disease in asymptomatic patients (screening). If the tests were appropriately ordered on the basis of the clinical presentation, any results should assist in including or excluding possible diagnoses. Test results may interfere with the clinical decision process if the test poorly discriminates between patients with and without the suspected disease(s) or if the test result is improperly integrated into the clinical context.
Laboratory tests are imperfect and may mistakenly identify some healthy people as diseased (a false-positive result) or may mistakenly identify some affected people as disease-free (a false-negative result). A test’s ability to correctly identify patients with a disease depends on how likely a person is to have that disease (prior probability) as well as on the test’s intrinsic operating characteristics (1).
Although diagnostic testing is often a critical contributor to accurate clinical decision making, testing can have undesired or unintended consequences. Testing should be done with deliberation and purpose and with the expectation that the test result will reduce ambiguity surrounding patient problems and contribute to their health. In addition to the risk of providing incorrect information (thereby delaying initiation of treatment or inducing unnecessary treatment), laboratory tests consume limited resources and may themselves have adverse effects (eg, pneumothorax caused by lung biopsy) or may prompt additional unnecessary testing or patient stress.
The results of a screening or diagnostic test should be interpreted in the specific clinical situation and in the context of prior baseline testing.
Reference
1. Armstrong KA, Metlay JP. Annals Clinical Decision Making: Using a Diagnostic Test. Ann Intern Med. 2020;172(9):604-609. doi:10.7326/M19-1940
Defining a Positive Test Result
Among the most common tests are those that provide results along a continuous, quantitative scale (eg, blood glucose, white blood cell count). Such tests may provide useful clinical information throughout their ranges, but clinicians often use them to diagnose a condition by requiring that the result be classified as positive or negative (ie, disease present or absent) based on comparison to some established criterion or cutoff point. Such cutoff points are usually selected based on statistical and conceptual analysis that attempts to balance the rate of false-positive results (prompting unnecessary, expensive, and possibly dangerous tests or treatments) and false-negative results (failing to diagnose a treatable disease). Identifying a cutoff point also depends on having a gold standard to identify the disease in question.
Typically, such quantitative test results (eg, white blood cell count in cases of suspected bacterial pneumonia) follow some type of distribution curve (not necessarily a normal curve, although commonly depicted as such). The distribution of test results for patients with disease is centered on a different point than that for patients without disease. Some patients with disease will have a very high or very low result, but most have a result centered on a mean. Conversely, some disease-free patients have a very high or very low result, but most have a result centered on a different mean from that for patients with disease. For most tests, the distributions overlap such that many of the possible test results occur in patients with and without disease; such results are more clearly illustrated when the curves are depicted on the same graph (see figure ). Some patients above and below the selected cutoff point will be incorrectly characterized. Adjusting a cutoff point to identify more patients with disease (increase test sensitivity) also increases the number of false positives (poor specificity), and moving the cutoff point the other way to avoid falsely diagnosing patients as having disease increases the number of false negatives. Each cutoff point is associated with a specific probability of true-positive and false-positive results.
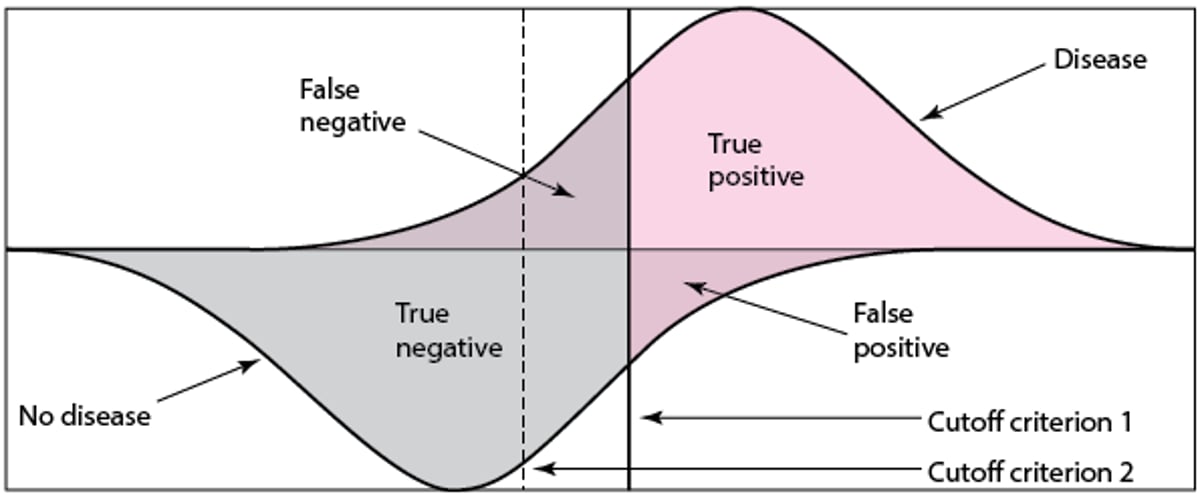
Distributions of Test Results
Patients with disease are shown in the upper distribution; patients without disease are shown in the lower distribution. For patients with disease, the region beneath the distribution of results that lies to the right of (above) the cutoff criterion corresponds to the test’s true-positive rate (ie, its sensitivity); the region that lies to the left of (below) the criterion corresponds to the false-negative rate. For patients without disease, the region to the right of the cut-off criterion corresponds to the false-positive rate, and the region to the left corresponds to the true-negative rate (ie, its specificity). For 2 overlapping distributions (eg, patients with and without disease), moving the cutoff criterion line affects sensitivity and specificity, but in opposite directions; changing the cutoff criterion from 1 to 2 decreases the number of false negatives (increases sensitivity) but also increases the number of false positives (decreases specificity). |

Receiver operating characteristic (ROC) curves
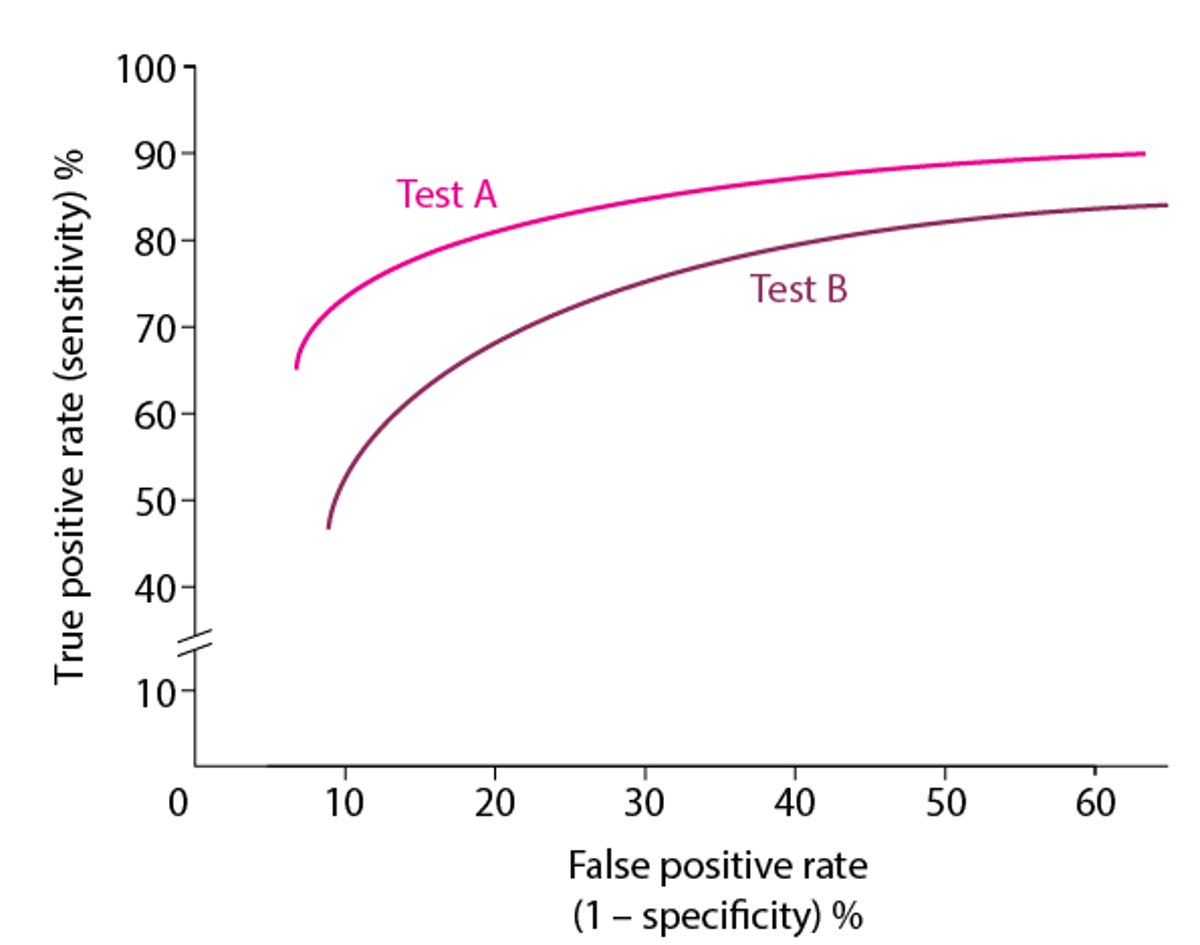
Graphing the fraction of true-positive results (number of true positives/number with disease) against the fraction of false-positive results (number of false positives/number without disease) for a series of cutoff points generates what is known as an ROC curve. The ROC curve graphically depicts the tradeoff between the sensitivity and specificity when the cut off point is adjusted (see figure ). By convention, the true-positive fraction is placed on the y-axis, and the false-positive fraction is placed on the x-axis. The greater the area under the ROC curve, the better the test discriminates between patients with or without disease.
ROC curves allow tests to be compared over a variety of cutoff points. In the example, Test A performs better than Test B over all ranges. ROC curves also assist in the selection of the cutoff point designed to maximize a test’s utility. If a test is designed to confirm a disease, a cutoff point with greater specificity and lower sensitivity is selected. If a test is designed to screen for occult disease, a cutoff point with greater sensitivity and lower specificity is selected.
Typical Receiver Operating Characteristic (ROC) Curve

Test Characteristics
Some clinical variables have only 2 possible results (eg, alive/dead, pregnant/not pregnant); such variables are termed categorical and dichotomous. Other categorical results may have many discrete values (eg, blood type, Glasgow Coma Scale) and are termed nominal or ordinal. Nominal variables such as blood type have no particular order. Ordinal variables such as the Glasgow Coma Scale have discrete values that are arranged in a particular order. Other clinical variables, including many typical diagnostic tests, are continuous and have an infinite number of possible results (eg, white blood cell count, blood glucose level). Many clinicians select a cutoff point that can cause a continuous variable to be treated as a dichotomous variable (eg, patients with a fasting blood glucose level > 126 mg/dL [7.0 mmol/L] are considered to have diabetes). Other continuous diagnostic tests have diagnostic utility when they have multiple cutoff points or when ranges of results have different diagnostic value.
When test results can be defined as positive or negative, all possible outcomes can be recorded in a simple 2×2 table (see table ) from which important discriminatory test characteristics, including sensitivity, specificity, positive and negative predictive value, and likelihood ratio (LR), can be calculated (see table ).
Distribution of Hypothetical Test Results
Results | Disease Present | Disease Absent |
|---|---|---|
Test positive | True positive | False positive |
Test negative | False negative | True negative |
Total patients | All patients with disease | All patients without disease |
Sensitivity, specificity, and predictive values
Sensitivity and specificity are typically considered characteristics of the test itself, independent of the patient population.
Sensitivity is the likelihood that patients with the disease will have a positive test result (true-positive rate).
Thus, a test that is positive in 8 of 10 patients with a disease has a sensitivity of 0.8 (also expressed as 80%). Sensitivity represents how well a test detects the disease; a test with low sensitivity does not identify many patients with disease, and a test with high sensitivity is useful to exclude a diagnosis when results are negative. Sensitivity is the complement of the false-negative rate (ie, the false-negative rate plus the sensitivity = 100%).
Specificity is the likelihood that patients without the disease will have a negative test result (true-negative rate).
Thus, a test that is negative in 9 of 10 patients without disease has a specificity of 0.9 (or 90%). Specificity represents how well a test correctly identifies patients with disease because tests with high specificity have a low false-positive rate. A test with low specificity diagnoses many patients without disease as having disease. It is the complement of the false-positive rate.
Predictive values describe test behavior in a given population of patients not knowing if they have the disease. For a given test, predictive values vary depending on the prevalence of disease in the patient population tested.
Positive predictive value (PPV) is the proportion of patients with a positive test that actually have disease.
Thus, if 9 of 10 positive test results are correct (true positive), the PPV is 90%. Because all positive test results have some number of true positives and some false positives, the PPV describes how likely it is that a positive test result in a given patient population represents a true positive.
Negative predictive value (NPV) is the proportion of patients with a negative test result that are actually disease free.
Sensitivity, Specificity, and Predictive Values
NPV = negative predictive value; PPV = positive predictive value. |


Thus, if 8 of 10 negative test results are correct (true negative), the NPV is 80%. Because not all negative test results are true negatives, some patients with a negative test result actually have disease. The NPV describes how likely it is that a negative test result in a given patient population represents a true negative.

Likelihood ratios (LRs)
Unlike sensitivity and specificity, which do not apply to specific patient probabilities, the LR allows clinicians to interpret test results in a specific patient provided there is a known (albeit often estimated) pre-test probability of disease.
The LR describes the change in pre-test probability of disease when the test result is known and answers the question
How much has the post-test probability changed from the pre-test probability now that the test result is known?
Many clinical tests are dichotomous; they are either above the cutoff point (positive) or below the cutoff point (negative) and there are only 2 possible results. Other tests give results that are continuous or occur over a range where multiple cutoff points are selected. The actual post-test probability depends on the magnitude of the LR (which depends on test operating characteristics) and the pre-test probability estimation of disease. When the test being done is dichotomous and the result is either positive or negative, the sensitivity and specificity can be used to calculate positive LR (LR+) or negative LR (LR-).
LR+: The ratio of the likelihood of a positive test result occurring in patients with disease (true positive) to the likelihood of a positive test result in patients without disease (false positive)
LR-: The ratio of the likelihood of a negative test result in patients with disease (false negative) to the likelihood of a negative test result in patients without disease (true negative)
When the result is continuous or has multiple cutoff points, the ROC curve, not sensitivity and specificity, is used to calculate an LR that is no longer described as LR+ or LR-.
Because the LR is a ratio of mutually exclusive events rather than a proportion of a total, it represents odds rather than probability. For a given test, the LR is different for positive and negative results.
For example, given a positive test result, an LR of 2.0 indicates the odds are 2:1 (true positives:false positives) that a positive test result represents a patient with disease. Of 3 positive tests, 2 would occur in patients with disease (true positive) and 1 would occur in a patient without disease (false positive). Because true positives and false positives are components of sensitivity and specificity calculations, the LR+ can also be calculated as sensitivity/(1 − specificity). The greater the LR+, the more information a positive test result provides; a positive result on a test with an LR+ > 10 is considered strong evidence in favor of a diagnosis. In other words, the pre-test probability estimation moves strongly toward 100% when a positive test has a high LR+.
For a negative test result, an LR- of 0.25 indicates that the odds are 1:4 (false negatives:true negatives) that a negative test result represents a patient with disease. Of 5 negative test results, 1 would occur in a patient with disease (false negative) and 4 would occur in patients without disease (true negative). The LR- can also be calculated as (1 −sensitivity)/specificity. The smaller the LR-, the more information a negative test result provides; a negative result on a test with an LR < 0.1 is considered strong evidence against a diagnosis. In other words, the pre-test probability estimation moves strongly toward 0% probability when a negative test has a low LR-.
Test results with LRs of 1.0 carry no information and cannot affect the post-test probability of disease.
LRs are convenient for comparing tests and are also used in Bayesian analysis to interpret test results. Just as sensitivity and specificity change as cutoff points change, so do LRs. As a hypothetical example, a high cutoff for white blood cell (WBC) count (eg, 30,000/mcL) in a possible case of acute appendicitis with perforation is more specific and would have a high LR+ but also a high (and thus not very informative) LR-; choosing a much lower and very sensitive cutoff (eg, 12,000/mcL) would have a low LR- but also a lower LR+.
Dichotomous Tests
An ideal dichotomous test would have no false positives or false negatives; all patients with a positive test result would have disease (100% PPV), and all patients with a negative test result would not have disease (100% NPV).
In reality, all tests have false positives and false negatives, some tests more than others. To illustrate the consequences of imperfect sensitivity and specificity on test results, consider hypothetical results (see table ) of urine dipstick leukocyte esterase testing in a group of 1000 women, 300 (30%) of whom have a urinary tract infection (UTI, as determined by a gold-standard test such as urine culture). This scenario assumes for illustrative purposes that the dipstick test has sensitivity of 71% and specificity of 85%.
Sensitivity of 71% means that only 213 (71% of 300) women with UTI would have a positive test result. The remaining 87 would have a negative test result. Specificity of 85% means that 595 (85% of 700) women without UTI would have a negative test result. The remaining 105 would have a positive test result. Thus, of 213 + 115 = 318 positive test results, only 213 would be correct (213/318 = 67% PPV); a positive test result makes the diagnosis of UTI more likely than not but not certain. There would also be 87 + 595 = 682 negative tests, of which 595 are correct (595/682 = 87% NPV), making the diagnosis of UTI much less likely but still possible; 13% of patients with a negative test result would actually have a UTI.
Distribution of Test Results of a Hypothetical Leukocyte Esterase Test in a Cohort of 1000 Women With an Assumed 30% Prevalence of UTI
Results | Disease Present | Disease Absent | Total Patients |
|---|---|---|---|
Test positive | True positive (TP) 213 patients (71% of 300) | False positive (FP) 105 patients (700 −595) | 318 patients with a positive test |
Test negative | False negative (FN) 87 patients (300 −213) | True negative (TN) 595 patients (85% of 700) | 682 patients with a negative test |
Total patients | 300 patients with UTI (assumed) | 700 patients without UTI (assumed) | 1000 patients |
Positive predictive value (PPV) = TP/(all patients with a positive test) = TP/(TP + FP) = 213/(213 + 105) = 67%. Negative predictive value (NPV) = TN/(all patients with a negative test) = TN/(TN + FN) = 595/(595 + 87) = 87%. Positive likelihood ratio (LR+) = sensitivity/(1 − specificity) =0.71/(1 − 0.85) =4.73. Negative likelihood ratio (LR-) = (1 − sensitivity)/specificity = (1 − 0.71)/0.85 = 0.34. UTI = urinary tract infection | |||
However, the PPVs and NPVs derived in this patient cohort cannot be used to interpret results of the same test when the underlying incidence of disease (pre-test or prior probability) is different. Note the effects of changing disease incidence to 5% (see table ). Now most positive test results are false, and the PPV is only 20%; a patient with a positive test result is actually more likely to not have a UTI. However, the NPV is now very high (98%); a negative result essentially excludes UTI.
Distribution of Test Results of a Hypothetical Leukocyte Esterase Test in a Cohort of 1000 Women With an Assumed 5% Prevalence of UTI
Results | Disease Present | Disease Absent | Total Patients |
|---|---|---|---|
Test positive | True positive (TP) 36 patients (71% of 50) | False positive (FP) 144 patients (950 −806) | 180 patients with a positive test |
Test negative | False negative (FN) 14 patients (50 −36) | True negative (TN) 806 patients (85% of 950) | 820 patients with a negative test |
Total patients | 50 patients with UTI (assumed) | 950 patients without UTI (assumed) | 1000 patients |
Positive predictive value (PPV) = TP/(all with a positive test) = TP/(TP + FP) = 36/(36 + 144) = 20%. Negative predictive value (NPV) = TN/(all with a negative test) = TN/(TN + FN) = 806/(806 + 14) = 98%. Positive likelihood ratio (LR+) = sensitivity/(1 − specificity) =0.71/(1 − 0.85) =4.73. Negative likelihood ratio (LR-) = (1 − sensitivity)/specificity = (1 − 0.71)/0.85 = 0.34. UTI = urinary tract infection | |||
Note that in both patient cohorts, even though the PPV and NPV are very different, the LRs do not change because the LRs are determined only by test sensitivity and specificity.
Clearly, a test result does not provide a definitive diagnosis but only estimates the probability of a disease being present or absent, and this post-test probability (likelihood of disease given a specific test result) varies greatly based on the pre-test probability of disease as well as the test’s sensitivity and specificity (and thus its LR).
Pre-test probability
Pre-test probability is not a precise measurement; it is based on clinical judgment of how strongly the symptoms and signs suggest the disease is present, what factors in the patient’s history support the diagnosis, and how common the disease is in a representative population. Many clinical scoring systems are designed to estimate pre-test probability; adding points for various clinical features facilitates the calculation of a score. These examples illustrate the importance of accurate pre-test prevalence estimation because the prevalence of disease in the considered population dramatically influences the test's utility. Validated, published prevalence-estimating tools should be used when they are available. For example, there are criteria for predicting pre-test probability of pulmonary embolism. Higher calculated scores yield higher estimated probabilities. In practice, determining the pre-test probability is facilitated by objective information, but may also be influenced by the clinician's skill and experience.
Continuous Tests
Many test results are continuous and may provide useful clinical information over a wide range of results. Clinicians often select a certain cutoff point to maximize the test’s utility. For example, a white blood cell (WBC) count > 15,000/mcL may be characterized as positive; values < 15,000/mcL as negative. When a test yields continuous results but a certain cutoff point is selected, the test operates like a dichotomous test. Multiple cutoff points can also be selected. Sensitivity, specificity, PPV, NPV, LR+, and LR- can be calculated for single or multiple cutoff points. The table illustrates the effect of changing the cutoff point of the WBC count in patients suspected of having appendicitis.
Effect of Changing the Cutoff Point of the WBC Count in Patients Suspected of Having Appendicitis
WBC Cutoff* | Sensitivity | Specificity | LR+ | LR- |
|---|---|---|---|---|
> 10,500 | 84% | 53.13% | 1.79 | 0.3 |
> 11,500 | 78% | 62.5% | 2.13 | 0.32 |
> 12,850 | 68% | 75% | 2.72 | 0.43 |
> 13,400 | 61.33% | 78.12% | 2.86 | 0.45 |
> 14,300 | 56.67% | 81.25% | 3.2 | 0.49 |
* Various cutoff points are selected for a continuous variable such as WBC count; results above the cutoff point are considered positive and those below the cutoff point are considered negative. Values listed are per microliter of blood. | ||||
LR = likelihood ratio; WBC = white blood cell. | ||||
Adapted from Keskek M, Tez M, Yoldas O, et al: Receiver operating characteristic analysis of leukocyte counts in operations for suspected appendicitis. American Journal of Emergency Medicine 26:769–772, 2008. | ||||
Alternatively, it can be useful to group continuous test results into levels. In this case, results are not characterized as positive or negative because there are multiple possible results, so although an LR can be determined for each level of results, there is no longer a distinct LR+ or LR-. For example, the table illustrates the relationship between WBC count and bacteremia in febrile children. Because the LR is the probability of a given result in patients with disease divided by the probability of that result in patients without the disease, the LR for each grouping of WBC count is the probability of bacteremia in that group divided by the probability of no bacteremia.
Using WBC Count Groups to Determine Likelihood Ratio of Bacteremia in Febrile Children*
WBC Count | Number of Children With Bacteremia, n = 127 (%) | Number of Children Without Bacteremia, N = 8629 (%) | LR (% With Bacteremia/% Without Bacteremia) |
|---|---|---|---|
0–5000 | 0 (0.0%) | 543 (6.3%) | 0.00 |
5,001–10,000 | 3 (2.4%) | 3291 (38.1%) | 0.06 |
10,001–15,000 | 15 (11.8%) | 2767 (32.1%) | 0.37 |
15,001–20,000 | 48 (37.8%) | 1337 (15.5%) | 2.4 |
20,001–25,000 | 34 (26.8%) | 469 (5.4%) | 4.9 |
25,001–30,000 | 12 (9.4%) | 155 (1.8%) | 5.3 |
> 30,001 | 15 (11.8%) | 67 (0.8%) | 15.2 |
* Incidence of bacteremia in 8756 febrile children grouped by WBC count (values listed are per microliter of blood). LR for each group is calculated by dividing the probability of bacteremia by the probability of no bacteremia. | |||
LR = likelihood ratio; WBC = white blood cell. | |||
Adapted from Lee GM, Harper MB. Risk of bacteremia for febrile young children in the post-Haemophilus influenzae type b era. Archives of Pediatric and Adolescent Medicine. 152:624–628, 1998. | |||
Grouping continuous variables allows for much greater use of the test result than when a single cutoff point is established. Using Bayesian analyses, the LRs in the table can be used to calculate the post-test probability.
For continuous test results, if an ROC curve is known, calculations as shown in the do not have to be done; LRs can be found for various points over the range of results using the slope of the ROC curve at the desired point.
Bayes Theorem
The process of using the pre-test probability of disease and the test characteristics to calculate the post-test probability is referred to as Bayes theorem or Bayesian revision. For routine clinical use, Bayesian methodology typically takes several forms:
Odds-likelihood formulation (calculation or nomogram)
Tabular approach
Odds-likelihood calculation
If the pre-test probability of disease is expressed as its odds and because a test’s LR represents odds, the product of the 2 represents the post-test odds of disease (analogous to multiplying 2 probabilities together to calculate the probability of simultaneous occurrence of 2 events):
Pre-test odds × LR = post-test odds
Because clinicians typically think in terms of probabilities rather than odds, probability can be converted to odds (and vice versa) with these formulas:
Odds = probability/1 − probability
Probability = odds/odds + 1
Consider the example of urinary tract infection (UTI) as given in the table , in which the pre-test probability of UTI is 0.3, and the test being used has an LR+ of 4.73 and an LR- of 0.34. A pre-test probability of 0.3 corresponds to odds of 0.3/(1 − 0.3) = 0.43. Thus, the post-test odds that a UTI is present in a patient with a positive test result equals the product of the pre-test odds and the LR+; 4.73 × 0.43 = 2.03, which represents a post-test probability of 2.03/(1 + 2.03) = 0.67. Thus, Bayesian calculations show that a positive test result increases the pre-test probability from 30% to 67%, the same result obtained in the PPV calculation in the table.
A similar calculation is done for a negative test; post-test odds = 0.34 × 0.43 = 0.15, corresponding to a probability of 0.15/(1 + 0.15) = 0.13. Thus, a negative test result decreases the pre-test probability from 30% to 13%, again the same result obtained in the NPV calculation in the table.
Many medical calculator programs that run on handheld devices are available to calculate post-test probability from pre-test probability and LRs.
Odds-likelihood nomogram
Using a nomogram is particularly convenient because it avoids the need to convert between odds and probabilities or create 2×2 tables.
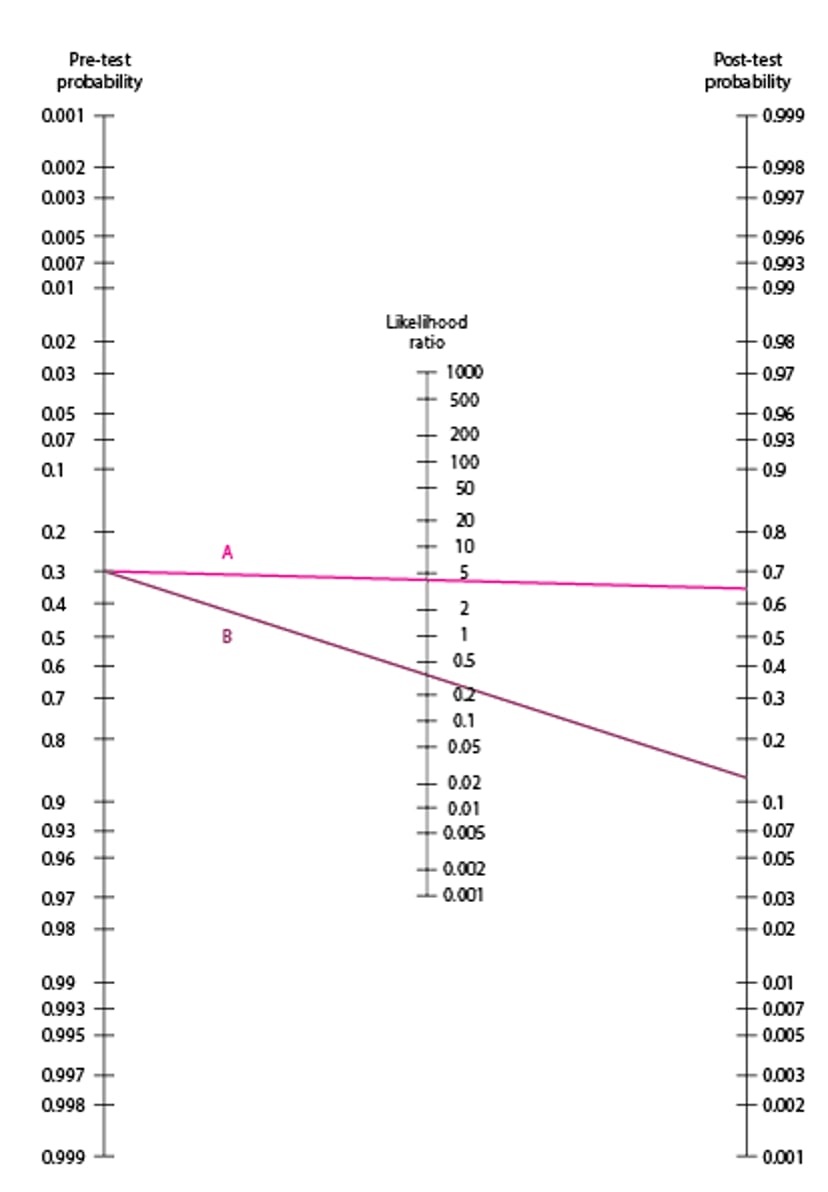
To use the , a line is drawn from the pre-test probability through the LR. The post-test probability is the point at which this line intersects the post-test probability line. Sample lines in the figure are drawn using data from the UTI test in the table . Line A represents a positive test result; it is drawn from pre-test probability of 0.3 through the LR+ of 4.73 and gives a post-test value of slightly < 0.7, similar to the calculated probability of 0.67. Line B represents a negative test result; it is drawn from pre-test probability of 0.3 through the LR- value of 0.34 and gives a post-test value slightly > 0.1, similar to the calculated probability of 13%.
Although the nomogram appears less precise than calculations, typical values for pre-test probability are often estimates, so the apparent precision of calculations is usually misleading.
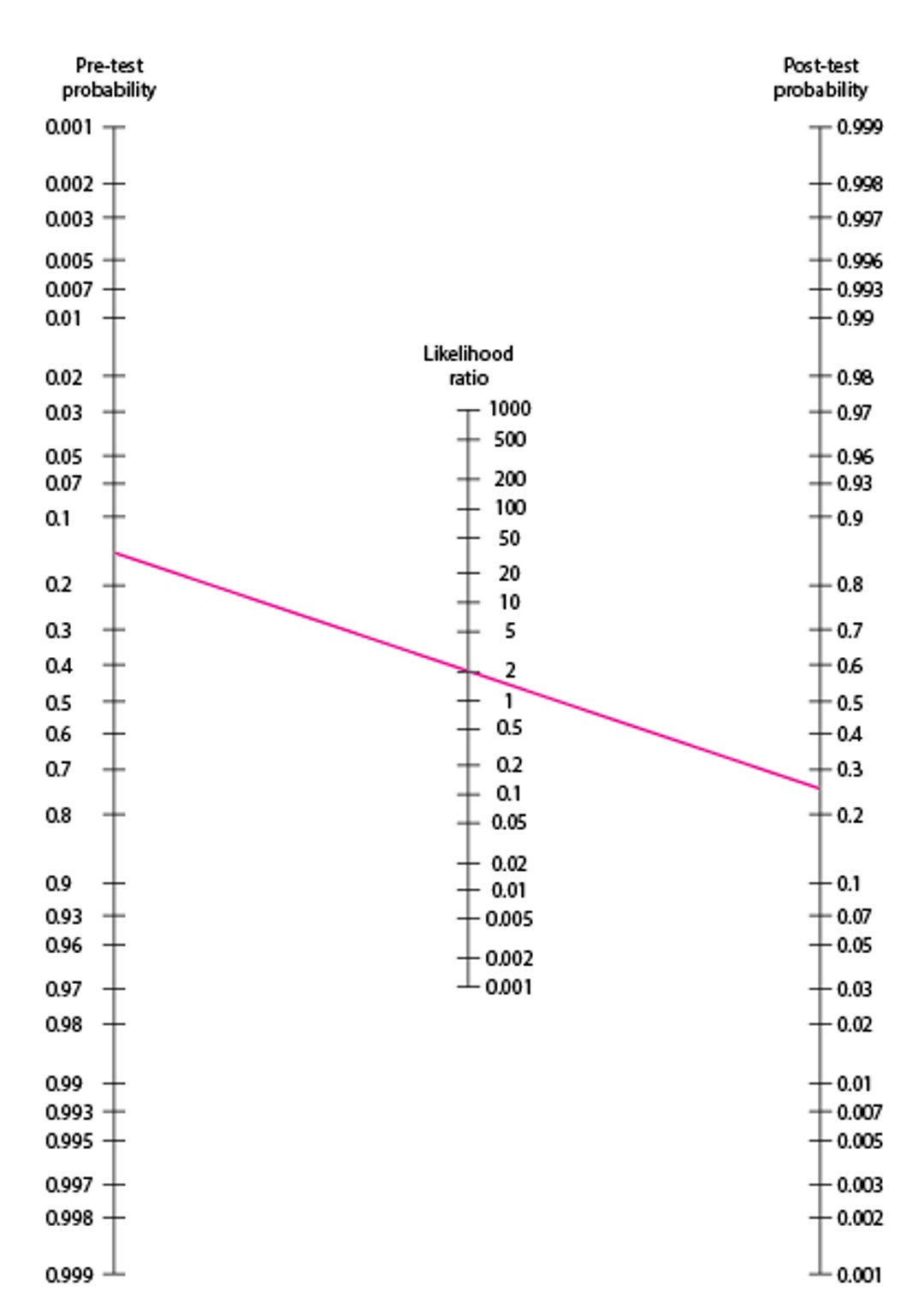
Fagan Nomogram
Illustrative lines are drawn using data from the urinary tract infection (UTI) test in the table Distribution of Test Results of a Hypothetical Leukocyte Esterase Test in a Cohort of 1000 Women With an Assumed 30% Prevalence of UTI. Line A represents a positive test result, drawn from a pre-test probability of 0.3 through an LR+ of 4.73 to a post-test value of slightly < 0.7, similar to the calculated probability of 0.67. Line B represents a negative test result drawn from pre-test probability of 0.3 through an LR- of 0.34 to a post-test value slightly > 0.1, similar to the calculated probability of 13%. LR+ = likelihood ratio for a positive result; LR- = LR for a negative result. Adapted from Fagan TJ. Letter: Nomogram for Bayes theorem. New England Journal of Medicine 293:257, 1975. |

Tabular approach
Often, LRs of a test are not known, but sensitivity and specificity are known, and pre-test probability can be estimated. In this case, Bayesian methodology can be done using a 2×2 table illustrated in the table using the example from the table . Note that this method shows that a positive test result increases the probability of a UTI to 67%, and a negative result decreases it to 13%, the same results obtained by calculation using LRs.
Interpretation of a Hypothetical Leukocyte Esterase (LE) Test Result in a Cohort of 1000 Women Assuming a 30% Prevalence of UTI (Pre-Test Probability), Test Sensitivity 71%, and Specificity 85%*
Results | UTI Present | UTI Absent |
|---|---|---|
300 patients with UTI | 700 patients without UTI | |
LE test positive | 213 patients (TP) | 105 patients (FP) |
LE test negative | 87 patients (FN) | 595 patients (TN) |
* Bayes theorem can be simplified to allow the calculation of post-test probability when pre-test probability is known:
| ||
FN = false negative; FP = false positive; TN = true negative; TP = true positive; UTI = urinary tract infection. | ||
Sequential Testing
Clinicians often do tests in sequence during many diagnostic evaluations. If the pre-test odds before sequential testing are known and the LR for each of the tests in sequence is known, post-test odds can be calculated using the following formula:
Pre-test odds × LR1 × LR2 × LR3 = post-test odds
This method is limited by the important assumption that each of the tests is conditionally independent of each other.
Screening Tests
Patients often must consider whether to be screened for occult disease. The premises of a successful screening program are that early detection improves a clinically significant outcome in patients with occult disease and that the false-positive results that may occur in screening do not create a burden (eg, costs and adverse effects of confirmatory testing, anxiety provoked by testing, unwarranted treatment) that exceeds such benefit. To minimize these possible burdens, clinicians must choose the proper screening test. Screening may not be appropriate when treatments or preventive measures are ineffective, unless the diagnosis may impact future life decisions for the patient or their family. If the disease is very uncommon, unless a subpopulation can be identified in which prevalence is higher, screening may not be cost effective; there are exceptions, such as in several genetic disorders that can be diagnosed and treated in the neonate.
Theoretically, the best test for both screening and diagnosis is the one with the highest sensitivity and specificity. However, such highly accurate tests are often complex, expensive, and invasive (eg, coronary angiography) and are thus not practical for screening large numbers of asymptomatic people. Typically, some tradeoff in sensitivity, specificity, or both must be made when selecting a screening test.
Whether a clinician chooses a test that optimizes sensitivity or specificity depends on the consequences of a false-positive or false-negative test result as well as the pre-test probability of disease. An ideal screening test is one that is always positive in nearly every patient with disease so that a negative result confidently excludes disease in healthy patients. For example, in testing for a serious disease for which an effective treatment is available (eg, coronary artery disease), clinicians would be willing to tolerate more false positives than false negatives (lower specificity and high sensitivity). Although high sensitivity is a very important attribute for screening tests, specificity also is important in certain screening strategies. Among populations with a higher prevalence of disease, the PPV of a screening test increases; as prevalence decreases, the post-test or posterior probability of a positive result decreases. Therefore, when screening for disease in high-risk populations, tests with a higher sensitivity are preferred over those with a higher specificity because they are better at excluding disease (fewer false negatives). On the other hand, in low-risk populations or for uncommon diseases for which therapy has lower benefit or higher risk, tests with a higher specificity are preferred.
Multiple screening tests
With the expanding array of available screening tests, clinicians must consider the implications of a panel of such tests. For example, test panels containing 8, 12, or sometimes 20 blood tests are often done when a patient is admitted to the hospital or is first examined by a new clinician. Although this type of testing may be helpful in screening patients for certain diseases, using the large panel of tests has potentially negative consequences. By definition, a test with a specificity of 95% gives false-positive results in 5% of healthy, normal patients. If 2 different tests with such characteristics are done, each for a different occult disease, in a patient who actually does not have either disease, the chance that both tests will be negative is 95% × 95%, or approximately 90%; thus, there is a 10% chance of at least one false-positive result. For 3 such tests, the chance that all 3 would be negative is 95% × 95% ×95%, or 86%, corresponding to a 14% chance of at least one false-positive result. If 12 different tests for 12 different diseases are done, the chance of obtaining at least one false-positive result is 46%. This high probability underscores the need for caution when deciding to do a screening test panel and when interpreting its results.
The same principle applies when ordering multiple sensitive but nonspecific tests (eg "autoimmune serologies" including antinuclear antibodies, antinuclear ribonucleoprotein [anti-RNP], rheumatoid factor) in the evaluation of patients with longstanding nonlocalizing and nonspecific symptoms, such as fatigue and generalized pain in the absence of physical examination findings or historical features suggesting a more specific rheumatologic diagnosis.
Testing Thresholds
A laboratory test should be done only if its results will affect management; otherwise the expense and risk to the patient are for naught. Clinicians can sometimes make the determination of when to test by comparing pre-test and post-test probability estimations with certain thresholds. Above a certain probability threshold, benefits of treatment outweigh risks (including the risk of mistakenly treating a patient without disease), and treatment is indicated. This point is termed the treatment threshold and is determined as described in Clinical Decision-Making Strategies: Probability Estimations and the Treatment Threshold. By definition, testing is unnecessary when pre-test probability is already above the treatment threshold. But testing is indicated if pre-test probability is below the treatment threshold as long as a positive test result could raise the post-test probability above the treatment threshold. The lowest pre-test probability at which this can occur depends on test characteristics (eg, LR+) and is termed the testing threshold.
Conceptually, if the best test for a serious disorder has a low LR+, and the treatment threshold is high, it is understandable that a positive test result might not move the post-test probability above the treatment threshold in a patient with a low but worrisome pre-test probability (eg, perhaps 10% or 20%).
For a numerical illustration, consider the previously described case of a possible acute myocardial infarction (MI) in which the balance between risk and benefit determined a treatment threshold of 25%. When the probability of MI exceeds 25%, thrombolytic therapy is given. When should a rapid echocardiogram be done before giving thrombolytic therapy? Assume a hypothetical sensitivity of 60% and a specificity of 70% for echocardiography in diagnosing an MI; these percentages correspond to an LR+ of 60/(100 − 70) = 2 and an LR- of (100 −60)/70 = 0.57.
The issue can be addressed mathematically (pre-test odds × LR = post-test odds) or more intuitively graphically by using the . On the nomogram, a line connecting the treatment threshold (25%) on the post-test probability line through the LR+ (2.0) on the middle LR line intersects a pre-test probability of approximately 0.14. Clearly, a positive test in a patient with any pre-test probability < 14% would still result in a post-test probability less than the treatment threshold. In this case, echocardiography would be useless because even a positive result would not lead to a decision to treat; thus, 14% pre-test probability is the testing threshold for this particular test (see figure ). Another test with a different LR+ would have a different testing threshold.
Fagan Nomogram Used to Determine Need to Test
In this example, a patient is assumed to have a treatment threshold (TT) of 25% for acute myocardial infarction (MI). When the probability of MI exceeds 25%, thrombolytic therapy is given. Clinicians can use the Fagan nomogram to determine when rapid echocardiography should be done before giving thrombolytic therapy. Assuming that echocardiography has a hypothetical sensitivity of 60% and a specificity of 70% for a new MI, these percentages correspond to a likelihood ratio (LR) of a positive test result (LR+) of 60/(100 − 70) = 2. A line connecting a 25% TT on the post-test probability line with LR+ (2.0) on the middle LR line intersects a pre-test probability of approximately 0.14. A positive test result in a patient with a pre-test probability of < 14% still results in a post-test probability of less than the TT. Adapted from Fagan TJ. Letter: Nomogram for Bayes theorem. New England Journal of Medicine 293:257, 1975. |

Depiction of Testing and Treatment Thresholds
Horizontal line represents post-test probability. |


Because 14% still represents a significant risk of MI, it is clear that a disease probability below the testing threshold (eg, a 10% pre-test probability) does not necessarily mean disease is excluded, just that a positive test result on the particular test in question would not change management and thus that test is not indicated. In this situation, the clinician would observe the patient for further findings that might elevate the pre-test probability above the testing threshold. In practice, because multiple tests are often available for a given disease, sequential testing might be used.
This example considers a test that of itself poses no risk to the patient. If a test has serious risks (eg, cardiac catheterization), the testing threshold should be higher; quantitative calculations can be done but are complex. Thus, decreasing a test’s sensitivity and specificity or increasing its risk narrows the range of probabilities of disease over which testing is the best strategy. Improving the test’s ability to discriminate or decreasing its risk broadens the range of probabilities over which testing is the best strategy.
A possible exception to the proscription against testing when pre-test probability is below the testing threshold (but is still worrisome) might be if a negative test result could reduce post-test probability below the point at which disease could be excluded. This determination requires a subjective judgment of the degree of certainty required to say a disease is excluded and, because low probabilities are involved, particular attention to any risks of testing.